Google does not have the time and resources to constantly review every single page on the web. With over 1 billion websites and the number constantly growing, Google has to be smart with their time!
Ever heard of a crawl budget? Crawl budget represents the set amount of time that search engines will spend going through pages on your site and the number of pages they will crawl. This can have a direct impact on your visibility within search engines. Your site’s crawl budget is roughly based on pagerank, meaning the pages that have the most links and activity are naturally going to have the most crawl budget given to them. Google has also stated they also consider two main factors:
Crawl Health: The more responsive your site is the more connections can be used to crawl your site. If the site slow or has trouble responding the limit will tend to decrease.
Set Limit: Within Search Console, site owners can set the crawl limit of their site. However, setting the limit as high as possible does not automatically increase the crawling.
If your website exceeds your allotted crawl budget, it’s possible that some of your key pages may not be crawled and indexed.In order to avoid this from happening, you need to make your site as easy for crawlers to process as possible by keeping crawl optimization in mind and addressing the areas where crawlers are most likely to get stuck.
Here are some quick methods for improving the crawlability of your site:
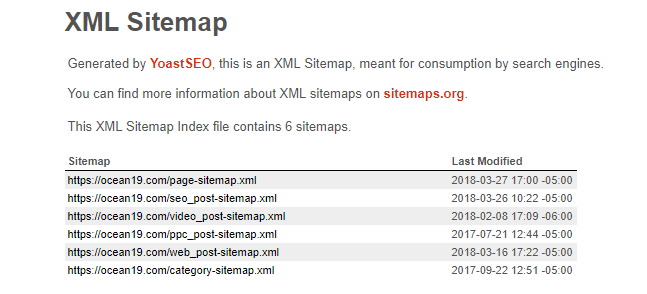
1. The XML Sitemap
All URLs listed in the sitemap should be the most up-to-date, canonical versions. Having crawlers dig through old and outdated links will take up space in your crawl budget. Removing all 4xx pages, unneeded redirects, non-canonical pages, and blocked pages can help save the crawlers a significant amount of time. This time is probably better used elsewhere on your site! Updating your XML sitemap as often as possible when changes are made is a simple and easy way to take some of the pressure off crawlers.
2. Pagination
In order for crawlers to understand the relationship between pages in series, rel=prev/next tags should be used on each page. If you are unfamiliar with these tags, basically they send signals to Google indicating that pages are part of a series, so that crawlers know which page to index. When you use these tags crawlers will not waste time crawling deeper, but will just send users to the first page in the series. Using the Robots.txt file to block off a certain section in a paginated series is also an option.
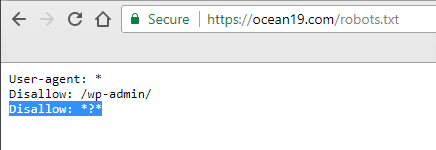
3. Internal Site Search
Using your Robots.txt file to block internal site search from being crawled is an excellent way to save crawlers’ time. Crawlers can waste an absorbent amount of time going through individual search result pages on your site. Having these individual searches indexed often provides no value to searchers, therefore reducing the need for crawlers to review these pages allows them to spend their time where needed.

4. Internal Redirects
Making sure all internal links are up-to-date is important for obtaining the highest possible rank for your pages. Every redirect that search engines have to follow create more work for the crawlers, and also saps a slight amount of SEO value from that page. Screaming Frog or other similar tools are an easy way to identify redirects across your site. Using a crawling tool like this allows you to get a better sense of how search engines access your site.
Redirect chains can also easily hang up crawlers. If there are several 301 or 302 redirects in a row, at some point, the crawler will stop following them. This could potentially mean that your end page does not get crawled and/or indexed. Try to do no more than one or two redirects in a row.
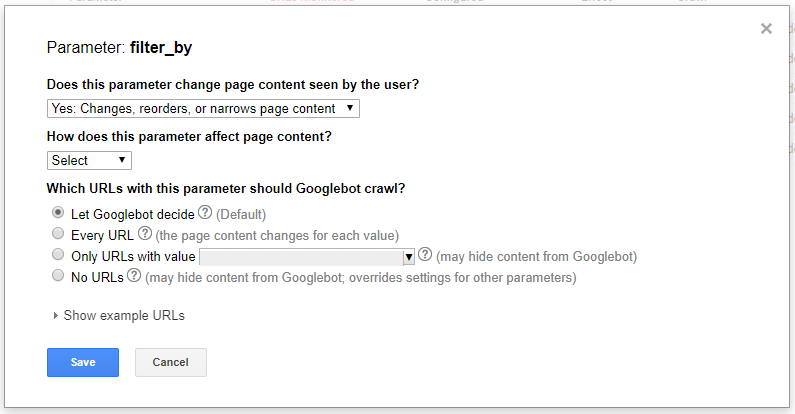
5. Parameters
Many content management systems generate dynamic URLs with parameters. However, by default, crawlers tend to see these as separate pages. If your site does use parameters, categorizing those parameters in Search Console can help crawlers understand how they should handle those pages. This is a quick and easy way to make sure crawlers are able to focus the crawl budget on the pages that matter and not the parameter versions of the same page.

6. Canonicals
It is a common misconception that applying a canonical tag prevents a page from being crawled by Google. Using a canonical tag prevents your page from being indexed, but pages with canonical tags are still being crawled, and eating up your budget in the process. Therefore, be conscious of where you are using canonical tags versus blocking the page entirely in the robot.txt file.
7.Site Architecture
Your URL structure and folder depth can also play a role in the number of pages crawlers access at a given time. If your URL structure leaves many of your important pages several layers deep it will take longer for crawlers to navigate there. Keeping your important pages easily navigable can help to ensure they are crawled and indexed.
8. Site Speed
Last, but not least, is site speed. One of the most effective measures of how long a crawler is able to spend on your site is how quickly it is able to pass through your pages. There are a variety of ways to increase speed on your site, including using a CDN, image compression, and browser caching. One of the best tools in identifying where to start when it comes to site speed it the PageSpeed Insights tool in Google’s Search Console.

Don’t leave all the hard work for the crawlers! Always remember, that while it may be easy for a human to understand your website, crawlers can be a different story. If you keep all these factors in mind, Google will be able to crawl and index your site with ease.